The PDF to text API that handles real-world documents.
Convert PDFs to clean text with one HTTP call. Scanned, multi-column, or faxed pages all return the same typed JSON. No templates to set up, no model to fine-tune.
Get started today for free. No credit card required.
Live demo
Try it on a real document.
Run OCR on a sample document, or drop in your own. No sign-up, no API key.
Or run it on your own document
Drop a document here
PDF, PNG, JPEG, TIFF, WebP, or BMP. Up to 4 MB, single page.
Or try a sample
See a scanned PDF become searchable text.
Use text mode when you need the words on each page for search, audit records, summarisation, or downstream LLM workflows.

MOTOR CLAIM NOTIFICATION
Policy number: POL-418209
Claimant: Daniel Harper
Incident date: 14/03/2026
Vehicle damage
Front bumper and left headlamp
reported after low-speed collision.
Estimated repair cost: $1,240Need fields instead of raw text? Switch to structured mode.
Send a JSON Schema with the same upload and the PDF comes back as typed fields: supplier, invoice number, totals, and repeating line items as arrays. Same endpoint, same async job, a different result shape.

{
"data": {
"supplier_name": "RIVERSIDE MEDICAL CENTRE",
"invoice_number": "INV-20416",
"date": "02/04/2026",
"patient": "M. Okafor",
"line_items": [
{
"service": "Office Visit",
"code": "99213",
"fee": "95.00"
},
{
"service": "ECG 12-lead",
"code": "93000",
"fee": "45.00"
},
{
"service": "Venepuncture",
"code": "36415",
"fee": "12.00"
},
{
"service": "Lipid Panel",
"code": "80061",
"fee": "38.00"
}
],
"total": "GBP 190.00"
}
}POST a PDF. Get page text, or structured JSON.
OCRWell processes PDFs asynchronously and returns typed JSON. Text mode gives you pages[] with the words on each page, ready to index, search, or pipe into an LLM. Send a schema instead and the same job returns the fields your app expects.
# Submit a PDF for text extraction
$ curl https://api.ocrwell.com/v1/documents \
-H "X-API-Key: $OCRWELL_KEY" \
-d '{"upload_id":"upl_01H7","mode":"text"}'{
"job": {
"id": "019539a6-6c3d-7e5f",
"status": "completed",
"mode": "text",
"page_count": 3
},
"result": {
"pages": [
{ "page": 1, "text": "INVOICE 4172..." },
{ "page": 2, "text": "Line items..." },
{ "page": 3, "text": "Totals..." }
]
}
}# Same upload, ask for structured fields
$ curl https://api.ocrwell.com/v1/documents \
-H "X-API-Key: $OCRWELL_KEY" \
-H "Content-Type: application/json" \
-d '{
"upload_id":"upl_01H7",
"mode":"structured",
"schema":{
"supplier_name":"",
"invoice_number":"",
"date":"",
"patient":"",
"line_items":[{"service":"","code":"","fee":""}],
"total":""
}
}'{
"job": {
"id": "019539a6-6c3d-7e5f",
"status": "completed",
"mode": "structured",
"page_count": 1
},
"result": {
"data": {
"supplier_name": "RIVERSIDE MEDICAL CENTRE",
"invoice_number": "INV-20416",
"date": "02/04/2026",
"patient": "M. Okafor",
"line_items": [
{ "service": "Office Visit", "code": "99213", "fee": "95.00" },
{ "service": "ECG 12-lead", "code": "93000", "fee": "45.00" },
{ "service": "Venepuncture", "code": "36415", "fee": "12.00" },
{ "service": "Lipid Panel", "code": "80061", "fee": "38.00" }
],
"total": "GBP 190.00"
}
}
}Where teams use the PDF to text API.
Index a back-catalogue
Run thousands of PDFs through the same endpoint. Idempotency keys and per-organisation rate limits keep bulk backfills safe alongside live traffic.
Feed LLMs with text, not pixels
Sending extracted text to Opus 4.7 costs a fraction of sending the raw PDF image. Cuts frontier-model input by up to 80% on document-heavy pipelines.
Scanned and faxed pages, too
Image-based PDFs, two-column reports, and faxed scans return the same shape as digital-native PDFs. No branching in your code.
Structured mode for fields
Send a JSON Schema and receive invoice numbers, dates, totals, and repeating line items as arrays instead of raw text, from the same endpoint.
Polling or signed webhooks
Poll GET /v1/jobs/:id while a user waits on your page, or receive an HMAC-signed callback when a batch job finishes. Built for queue workers and async pipelines.
Short-lived storage, no training
Uploaded PDFs are deleted after processing and results expire after retrieval. Your documents are never used to train AI models.
PDF to text API questions.
Does the PDF to text API handle scanned and image-based PDFs?
Yes. When a PDF has no embedded text layer, such as a scan or a faxed page, OCRWell runs OCR on the page images and returns the same page-by-page text it would for a digital-native PDF. There is no separate endpoint or flag to set.
What does the response look like?
In text mode the job returns a result.pages array with the text from each page in order, plus a page_count. You can index it, search it, or pass it straight to a model.
Can I send the extracted text straight to an LLM or RAG pipeline?
Yes, and it is far cheaper than sending page images. Text is grouped by page, so it chunks cleanly for embeddings, and sending text rather than pixels cuts frontier-model input cost on document-heavy workloads.
How large a PDF can I send, and how is it priced?
Files can be up to 20 MB. Pricing is per page processed, and the free forever tier covers 200 OCR pages per month.
What if I need structured fields instead of raw text?
Submit the same upload in structured mode with a JSON Schema and the job returns typed fields and arrays. For ready-made shapes, see the invoice, bank statement, and table extraction APIs.
Start free. Pay only when you scale.
- No credit card required.
- Hard cap, no overage charges.
- Paid plans from $20/mo when you grow.
Explore nearby OCR workflows.
OCR API
The general OCR API. Choose raw page text or schema-shaped JSON per job.
Image to text API
Read text from phone photos, screenshots, signage, scans, and image uploads.
Scanned PDF OCR API
Convert image-based and faxed PDFs that have no embedded text layer.
Invoice OCR API
Extract supplier details, invoice numbers, tax, totals, and line items.
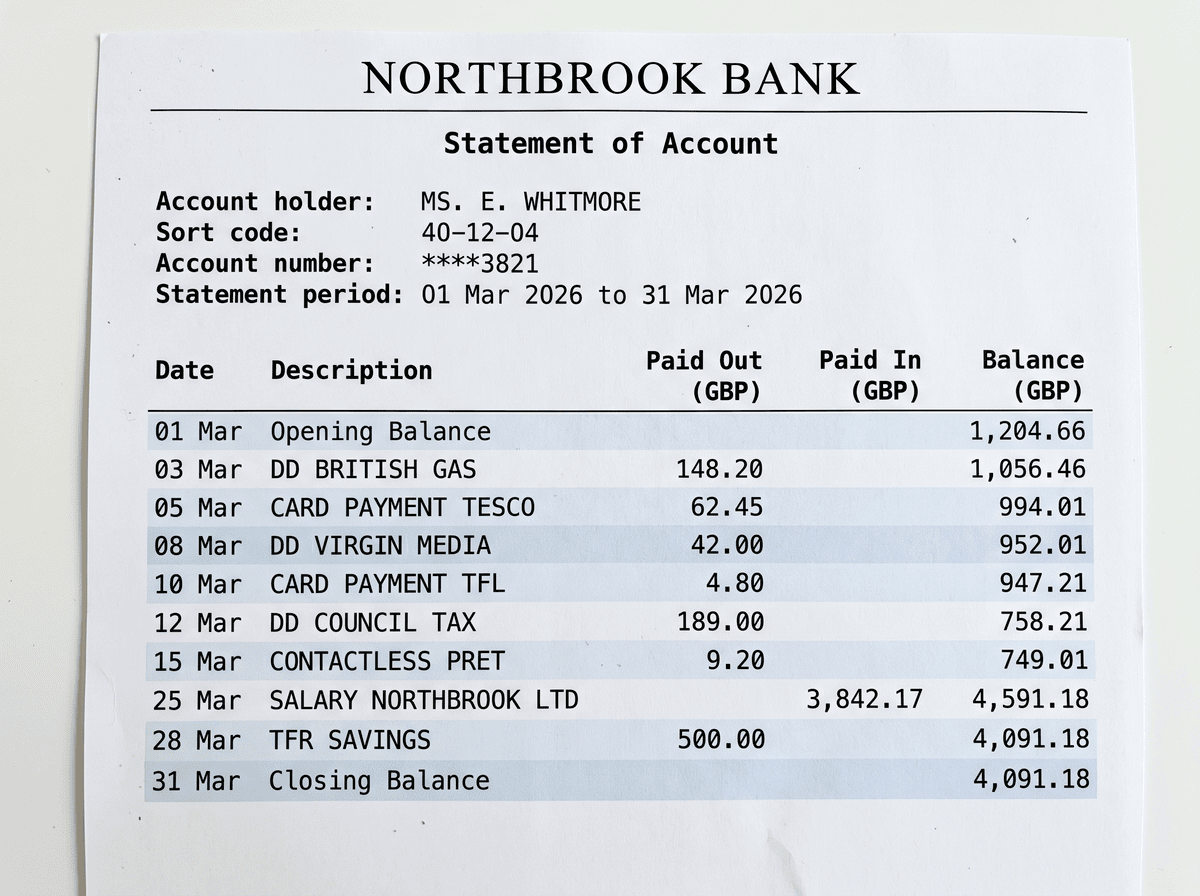
Bank statement OCR API
Extract account metadata, balances, and transaction rows from statements.
Table extraction API
Turn repeated rows in documents into structured JSON arrays.
Turn your PDFs into text today.
Generate an API key, send your first document, and have page-by-page text back in seconds. Free forever tier covers 200 OCR pages per month.